
모안정(모르면 안되는 정보 모음)
[Python] 빠르고 누락없이 Youtube 댓글 크롤링하기 본문
유튜브 댓글을 크롤링하는 작업을 하기 위해서
파이썬으로 유튜브 댓글을 가져오는 방법을 찾던 중 아래 사이트에서 많은 도움을 받아 구현을 하였습니다.
[Python]Selenium을 사용하여 유튜브 댓글 가져오기
제가 즐겨보는 Youtube B Man채널에서 제 최애 영화인 어벤져스 엔드게임의 영화 명장면을 정리한 어벤져스 엔드게임 명장면 총정리라는 영상의 댓글 가져오기를 해보았습니다. 인스타그램 크롤링
somjang.tistory.com
정말 자세하게 알려주셔서 많은 도움이 되었지만,
댓글 수가 많으면 크롤링하는데에 소요되는 시간이 매우 길었고,
인터넷 상태에 따라서 중간에 크롤링이 종료되는 현상이 있었습니다.
이러한 문제점들을 개선한 코드를 작성하고 정상적으로 동작을 확인하여 공유드리고자 포스팅합니다.
[기존 유튜브 댓글 크롤링 방법]
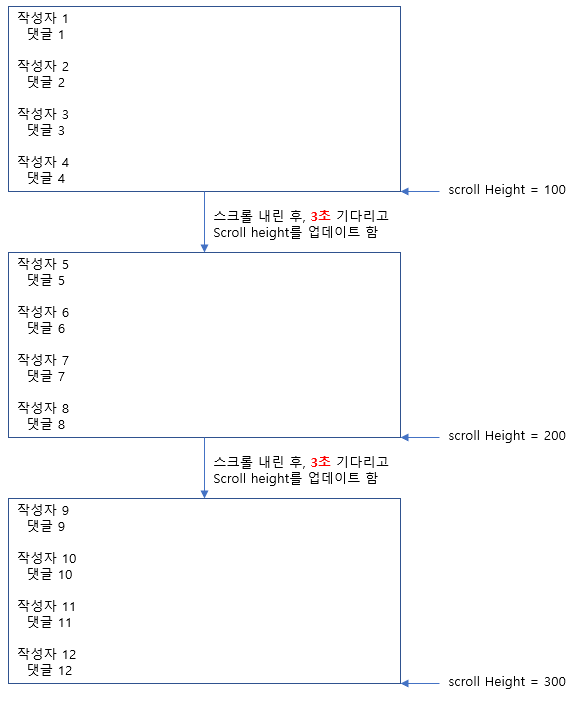
대부분의 블로그에 포스팅된 유튜브 댓글 크롤링 방법은 다음과 같습니다.
1. 유튜브 페이지를 열고
2. 스크롤을 페이지 제일 밑까지 내리고 (모든 댓글이 한 페이지에 들어오도록)
3. 댓글을 크롤링한다
저는 "2번" Step인 스크롤을 페이지 제일 밑까지 내리는 방법이 비 효율적이다 라고 생각을 했어요.
스크롤을 그냥 빠르게 제일 끝까지 내리면 되는데 왜 한번 내릴 때마다 3초를 기다려야 할까?라고요!
물론 인터넷 환경이 느리거나 하면 3초 안에 loading이 되지 않을 수 있고,
구현된 로직 자체가 "last_height == scroll height"인 경우 중단되기 때문에 안정성을 고려했기 때문이겠죠.
하지만, 여러분 컴퓨터에서 유튜브 댓글을 내려보면 사실 0.5초도 걸리지가 않습니다!
지금부터 이 시간을 최대한 줄이며, 안전하게 맨 밑의 댓글까지 스크롤을 내릴 수 있는 방법을 소개합니다.
[Queue] 활용
Queue는 여러분들도 익히 들어 알고 계시듯이, 선입 선출 방식의 자료 구조입니다.
이러한 특징을 가진 Queue를 활용하면 위 문제를 해결할 수 있는데요~
코드를 보며 어떻게 Queue를 활용하는지 알려드리겠습니다.

기본적인 콘셉트는 위 그림과 같습니다.
이렇게 구현을 하는 경우, Scroll이 내려갔는지 확인을 0.1초 단위로 수행할 수 있고
그만큼 빠른 주기로 스크롤을 내릴 수 있다는 장점이 있습니다.
또한, Max Queue Size를 조절하여 스크롤을 모두 내렸다고 판단할 수 있는 시간을 조절할 수 있어
스크롤을 내리다 중간에 멈추는 현상을 개선할 수 있습니다.
[크롤러 코드]
코드는 다음과 같습니다.
성능을 측정해보았습니다. 영상의 Scroll을 끝까지 내리고 BeautifulSoup을 통해 HTML Parsing까지 하는 기준입니다.
댓글 1700개 : 102 sec (1분 42초)
댓글 17000개 : 513 sec (8분 33초)
이 정도면 굉장한 속도 아닌가요? ㅎㅎ
1700개짜리 댓글을 내리는 데에는 Scroll update가 총 73번 일어나는데요,
기존 방식 대로라면 73 * 3 하여 219초가 소요되는데 거의 절반 수준으로 줄어들었습니다. (안정성도 덤으로!)
만족하셨다면 댓글 남겨주시면 저에게 큰 힘이 됩니다.
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from tqdm import tqdm
import time
import re
import requests
import random
#Queue의 기본적인 기능 구현
class Queue():
def __init__(self, maxsize):
self.queue = []
self.maxsize = maxsize
# Queue에 Data 넣음
def enqueue(self, data):
self.queue.append(data)
# Queue에 가장 먼저 들어온 Data 내보냄
def dequeue(self):
dequeue_object = None
if self.isEmpty():
print("Queue is Empty")
else:
dequeue_object = self.queue[0]
self.queue = self.queue[1:]
return dequeue_object
# Queue에 가장 먼저들어온 Data return
def peek(self):
peek_object = None
if self.isEmpty():
print("Queue is Empty")
else:
peek_object = self.queue[0]
return peek_object
# Queue가 비어있는지 확인
def isEmpty(self):
is_empty = False
if len(self.queue) == 0:
is_empty = True
return is_empty
# Queue의 Size가 Max Size를 초과하는지 확인
def isMaxSizeOver(self):
queue_size = len(self.queue)
if (queue_size > self.maxsize):
return False
else :
return True
if __name__=="__main__":
#set option of selenium
options = webdriver.ChromeOptions()
options.add_argument('window-size=1920x1080')
options.add_argument('disable-gpu')
options.add_argument('user')
options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
options.add_argument("lang=ko_KR")
driver = webdriver.Chrome(ChromeDriverManager().install(), chrome_options=options)
#target of crawling
data_list = []
driver.get("https://www.youtube.com/watch?v=QndOyQtTHUQ")
#페이지 Open 후 기다리는 시간
time.sleep(5.0)
#down the scroll
body = driver.find_element_by_tag_name('body')
last_page_height = driver.execute_script("return document.documentElement.scrollHeight")
# max size 50의 Queue 생성
# 0.1sec * 50 = 5sec 동안 Scroll 업데이트가 없으면 스크롤 내리기 종료
szQ = Queue(50)
enqueue_count = 0
while True:
# Scroll 내리기
driver.execute_script("window.scrollTo(0, document.documentElement.scrollHeight);")
# Scroll Height를 가져오는 주기
time.sleep(0.1)
new_page_height = driver.execute_script("return document.documentElement.scrollHeight")
# Queue가 꽉 차는 경우 스크롤 내리기 종료
if(enqueue_count > szQ.maxsize):
break
# 첫 Loop 수행 (Queue가 비어있는 경우) 예외 처리
if(szQ.isEmpty()) :
szQ.enqueue(new_page_height)
enqueue_count += 1
# Queue에 가장 먼저 들어온 데이터와 새로 업데이트 된 Scroll Height를 비교함
# 같으면 그대로 Enqueue, 다르면 Queue의 모든 Data를 Dequeue 후 새로운 Scroll Height를 Enqueue 함.
else :
if(szQ.peek() == new_page_height) :
szQ.enqueue(new_page_height)
enqueue_count += 1
else :
szQ.enqueue(new_page_height)
for z in range(enqueue_count) :
szQ.dequeue()
enqueue_count = 1
# 기존의 Scroll 내리는 방식
#if new_page_height == last_page_height:
# break
#last_page_height = new_page_height
#time.sleep(2.0)
# print ("[PASS] Get all comments of URL")
html0 = driver.page_source
driver.close()
html = BeautifulSoup(html0, 'html.parser')
comments_list = html.findAll('ytd-comment-thread-renderer', {'class':'style-scope ytd-item-section-renderer'})
# print (comments_list)
for j in range(len(comments_list)):
#contents of comment
comment = comments_list[j].find('yt-formatted-string',{'id':'content-text'}).text
comment = comment.replace('\n', '')
comment = comment.replace('\t', '')
#print(comment)
youtube_id = comments_list[j].find('a', {'id': 'author-text'}).span.text
youtube_id = youtube_id.replace('\n', '')
youtube_id = youtube_id.replace('\t', '')
youtube_id = youtube_id.strip()
raw_date = comments_list[j].find('yt-formatted-string', { 'class': 'published-time-text above-comment style-scope ytd-comment-renderer'})
date = raw_date.a.text
try:
like_num = comments_list[j].find('span', {'id': 'vote-count-middle', 'class': 'style-scope ytd-comment-action-buttons-renderer', 'aria-label': re.compile('좋아요')}).text
like_num = like_num.replace('\n', '')
like_num = like_num.replace('\t', '')
like_num = like_num.strip()
except: like_num = 0
data = {'youtube_id': youtube_id, 'comment': comment, 'date': date, 'like_num': like_num}
data_list.append(data)
result_df = pd.DataFrame(data_list, columns=['youtube_id','comment','date','like_num'])
result_df.to_excel("./Excel_Data/data.xlsx", index = False)
'Tip' 카테고리의 다른 글
| 아이폰 스팸 전화 차단 & 스팸 문자 차단 방법 (0) | 2021.12.06 |
|---|---|
| [모니터 주사율/종횡비 설정] NVIDIA 제어판 활용 (0) | 2021.12.03 |
| [우&우] 정자역 소고기 맛집 (0) | 2021.11.26 |
| [다빈치 리졸브, DaVinci Resolve] 디졸브가 안되는 경우 (2) | 2021.11.25 |
| [다빈치 리졸브, DaVinci Resolve] 유튜브 동영상 편집 툴 다운 받기 (0) | 2021.11.17 |



